
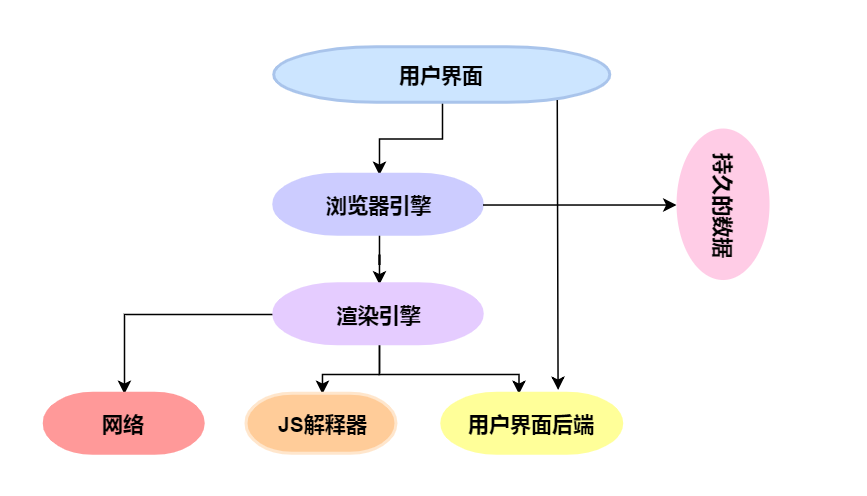
解析: 是呈现引擎最重要的环节。解析的目的就是为了把文档转换成有意义的结构,并且可以让代码理解和使用。通常解析后的结果代表了文档结构的节点数,称为解析树或者语法树
语法: 是解析的时候遵循文档的语法规则或者编写文档所用的语言、格式等的基础
解析过程: 词法分析器和语法分析器
解析是一个迭代的过程翻译: 将输入的文档转换成另一种格式:如将源码解析成解析树,然后解析树翻译成机器代码文档
最基本的有两种类型的解释器
关于自动生成解释器
有一些工具可以帮我们生成解释器,这些工具叫解释器生成器,只需要我们提供词汇和语法规则,他就会生成对应的解释器生成器。
webkit使用了两种非常有名的解释器生成器 Flex 和 Bison(或者叫:Lex、Yacc别名)
BNF 格式的语法规则实际上 HTML 并不符合与上下文无关(即不符合 BNF 的格式语法)所以,基本上常规的解释器都无法使用于 HTML (但是他们可以解析 css 和 js)
有一种可以定义 HTML 的正规格式叫 DTD (Document Type Definition, 文档类型), 但它不是与上下文无关语法
浏览器无法用自上而下或自下而上的解析器进行解析 HTML 的原因:
document.write 就会添加额外的标记,这样解析的输入内容实际上就发生了变化